Web3 Analytics is Broken
The next generation of the Web deserves the next generation of Analytics. What we’ve gotten for Web3 is — at best — recycled Web2 with MacGyvered usability.

Ethos of Web3
Web3 delivered on decentralized and permissionless innovation, democratizing the creation of data that is censorship resistant. Anyone can deploy any contract on any chain, composing any other, as the barriers to execution and data creation have been torn down.
Web3 also promised trust and transparency of this permissionless execution, allowing for the creation and control of your own data. All of this data is technically available for anyone to verify and analyze, but is actually gated by technical complexity and broken UX, making trust and transparency for all but the most sophisticated users more dream than reality. If the average Web3 user doesn’t have easy and practical access to data on chain, how can they trust and verify, let alone control their own data?
To fulfill Web3’s unmet promises, a new generation of analytics needs to be built from the ground up prioritizing its unique usability challenges and technical considerations for both users and builders. HyperArc is that new generation.
If the average Web3 user doesn’t have easy and practical access to data on chain, how can they trust and verify, let alone control their own data?
Recycling Web2
The blockchain is the ultimate decentralized transactional execution engine. It’s prioritization of immutability, transparency, and consensus of execution trades off on search and aggregation of the ledger itself. The blockchain allows anyone to quickly verify a single transaction if they know its hash. However, it’s not feasible to search for transactions that fit a specific criteria or to aggregate across transactions (sometimes at massive scale) to spot outliers and signals.
Products like The Graph and earlier versions of Dune balance these trade offs by recycling SQL databases like Postgres for their mature search and aggregation capabilities. However, these OLTP (Online Transaction Processing) databases are similarly optimized for their namesake — transactions. And, specifically, the more rigorous ACID transaction makes many of the same guarantees as a blockchain, from atomicity to durability. So recycling the Web2 analogy of a blockchain to address its own tradeoffs is only going to go so far.
The better counterpart to OLTP is OLAP (Online Analytical Processing). OLAP relaxes ACID as it’s no longer the source of truth (the blockchain is), and can instead optimize for speed and scale for search and analytics. To move and index data from the blockchain to OLAP requires ELT (Extract, Load, Transform) with many incumbents relying on Databricks, Spark, or DBT. These are powerful, but generic and dev-centric tools, all sharing a lowest common denominator in UX — SQL.
SQL is a hammer designed to perform any data manipulation, but being a hammer makes everything, including Web3, look like just another nail. SQL (and similarly GraphQL) sacrifices usability for flexibility. Recycling Web2 is a good first step in bringing transparency as it makes many things technically possible, but the ubiquitous recycling of SQL based UX betrays the ethos of Web3 by only empowering the few with the data.
HyperArc
HyperArc is the first analytical platform that prioritizes usability to make it possible for all users, not just the most technical, to have transparent access to the blockchain. This fixes the analytics experience that is broken today. So enough acronyms, lets see what HyperArc can do.
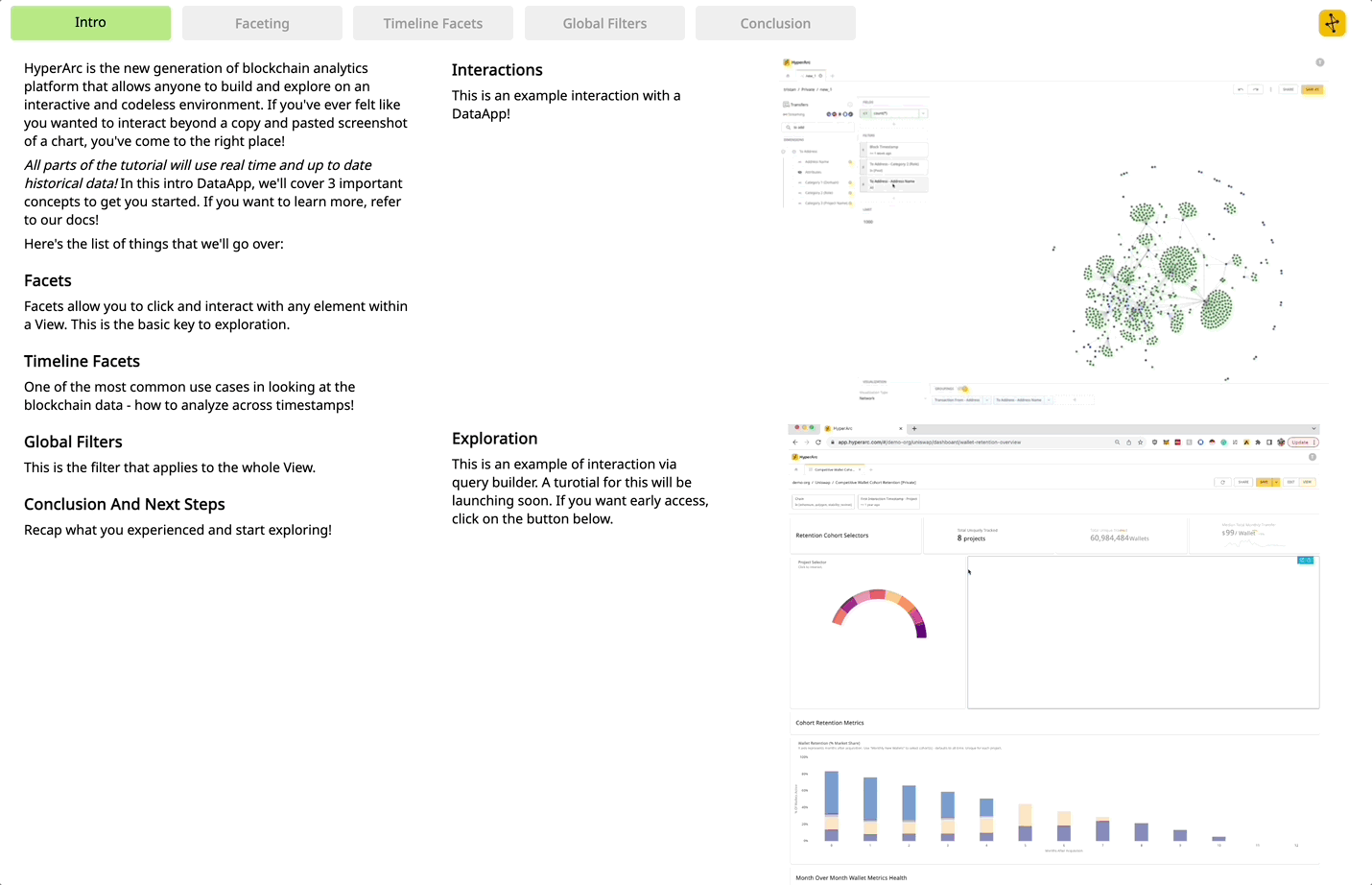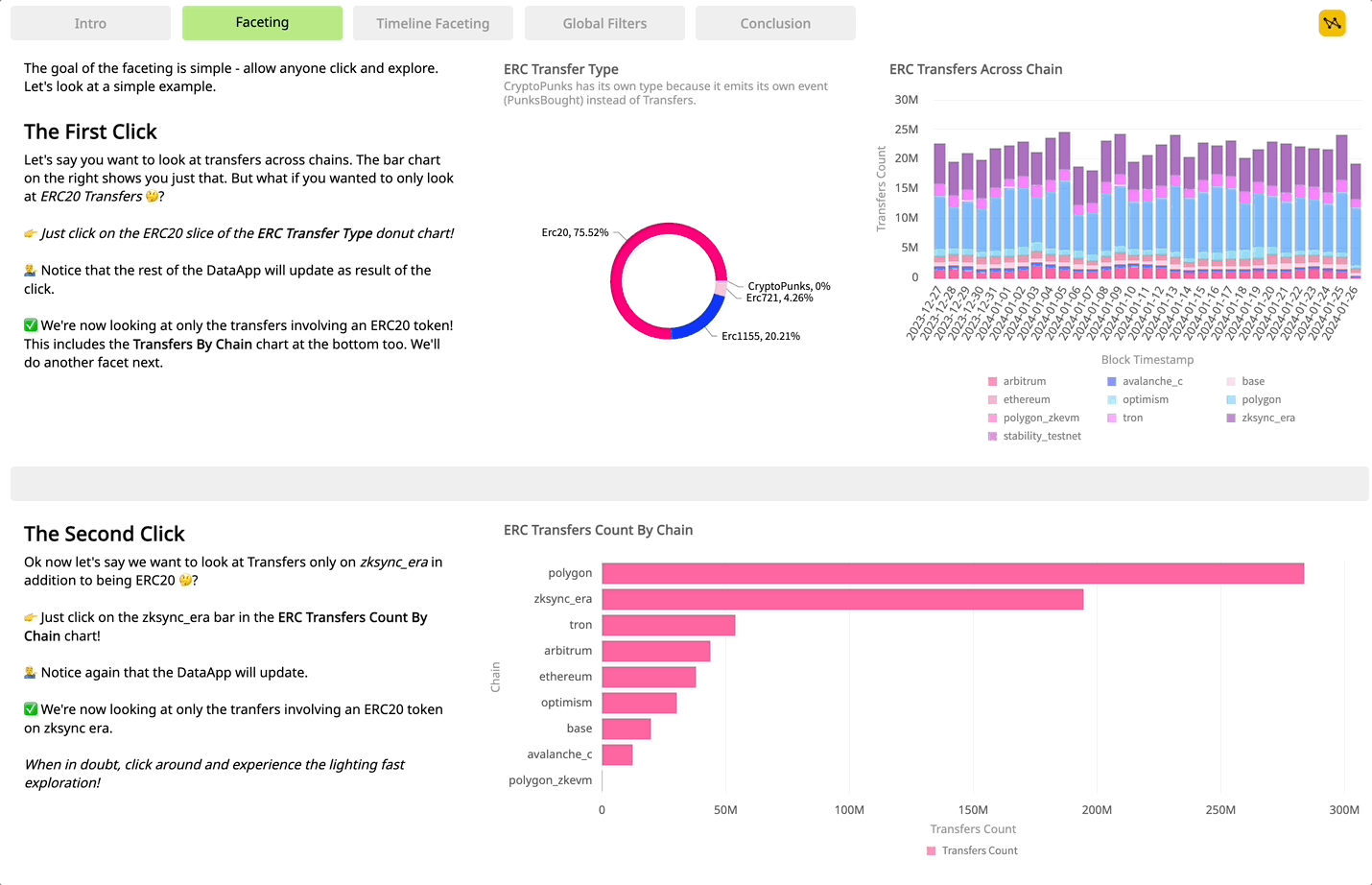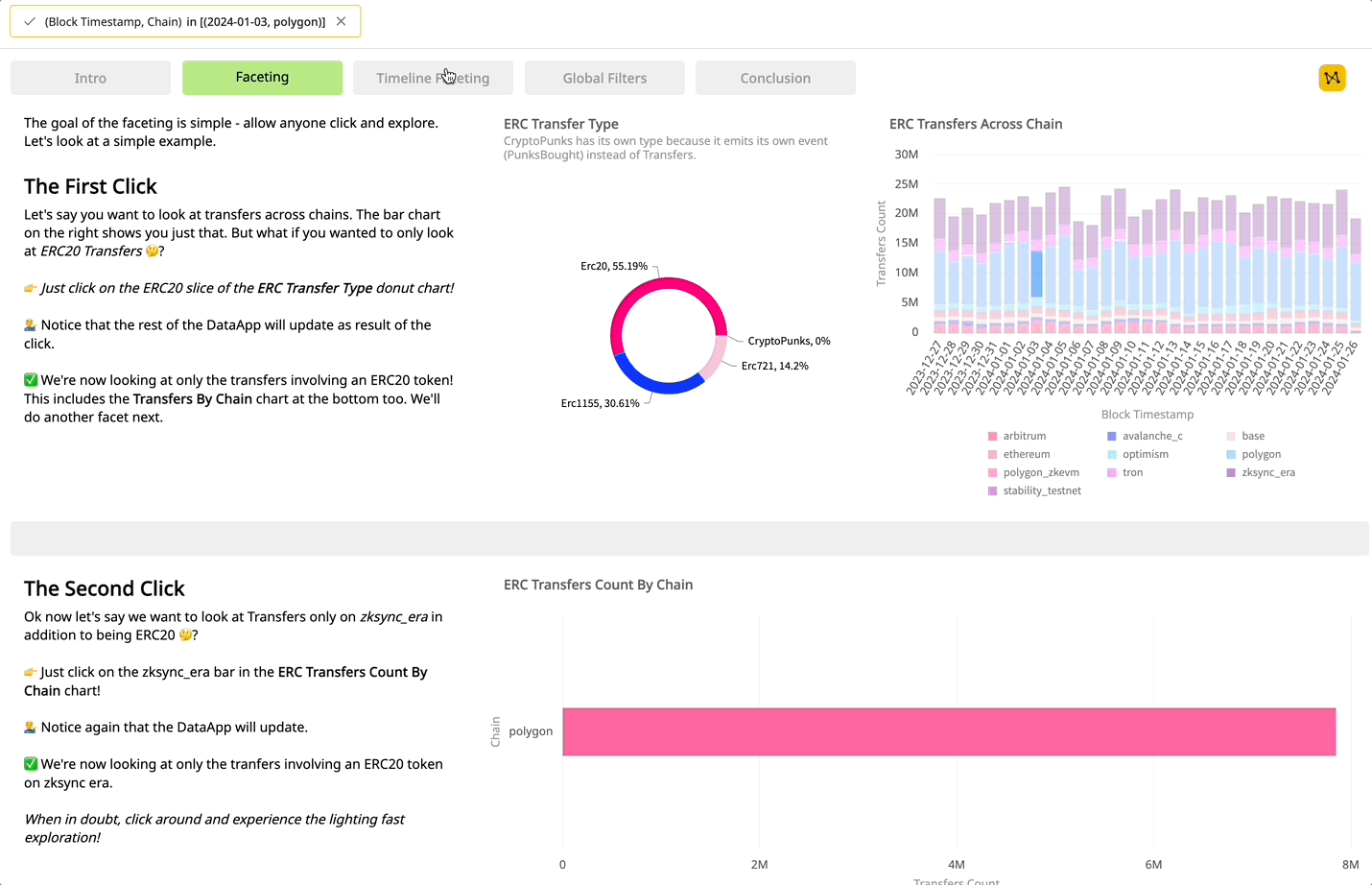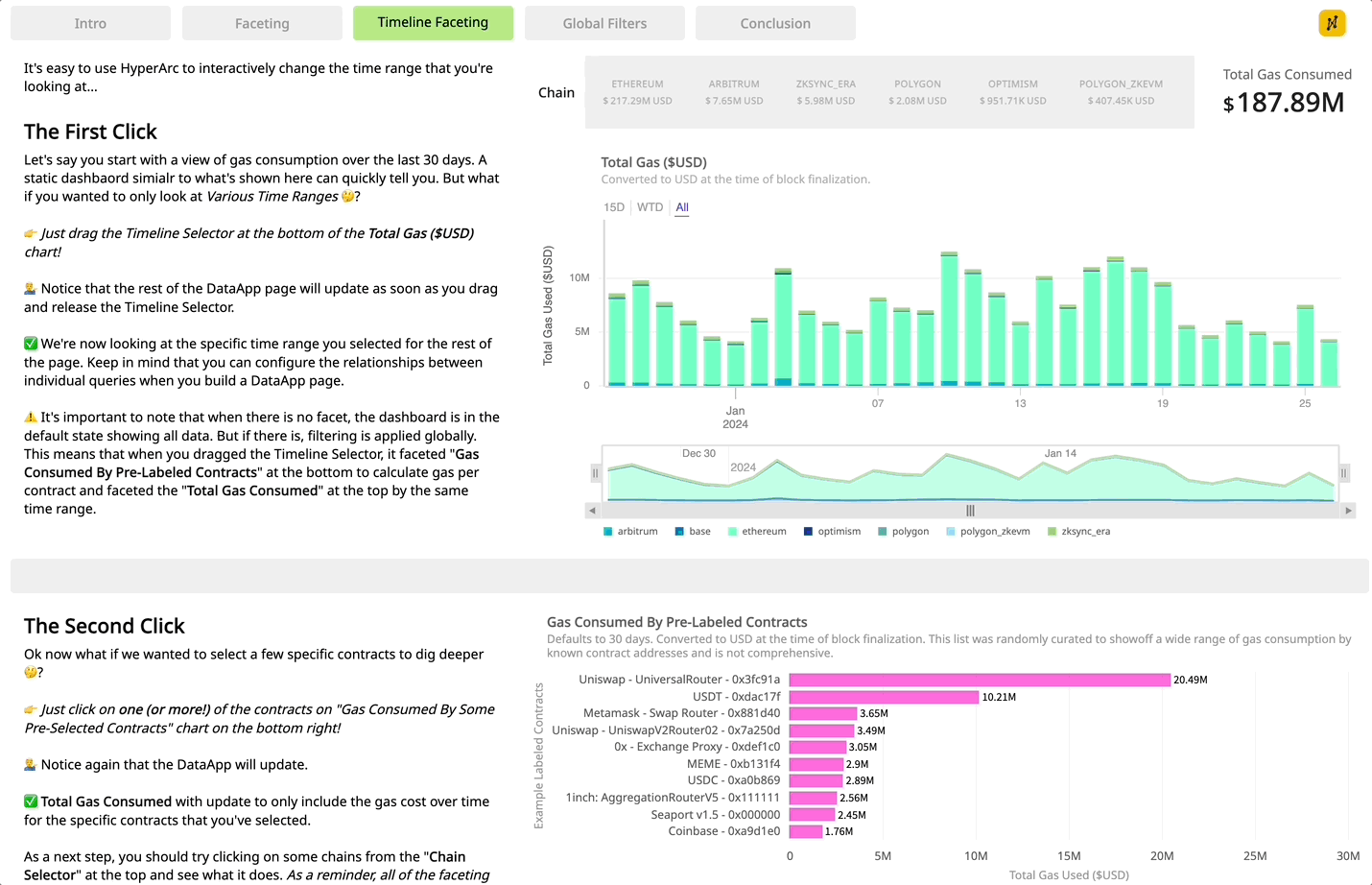
With our query builder you can quickly explore, compose, and iterate in real time to search and discover new insights across multiple chains. Without SQL, your growing queries never lock you into their own complexity as filters, metrics, groupings, and expressions are all modular and can be added or removed independently at anytime.
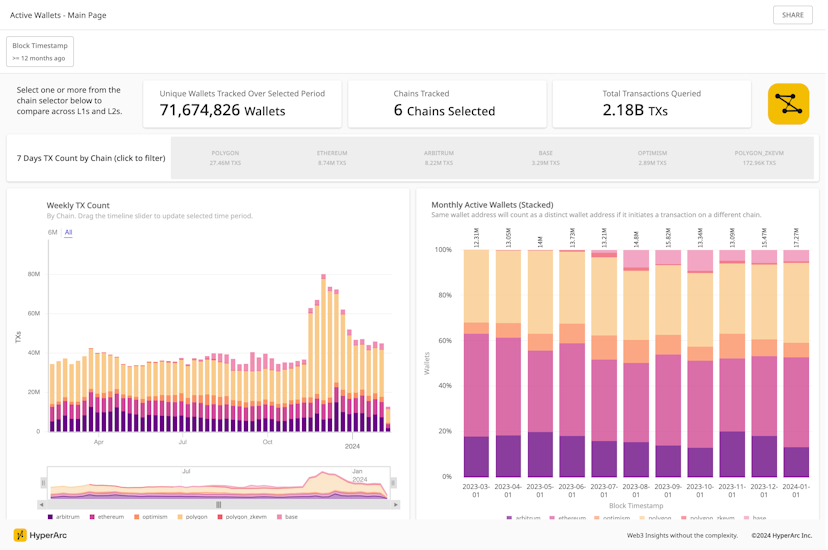
The image below shows how, in seconds, we can start from an overview of all 20B transfers across 10 chains, drilling into those of a specific chain and day, before looking at the network graph of those transfers by USD value.
Click to enlarge
Since our queries are declarative and not code, you can simply compose them in our app builder for out-of-the box interactivity. And your users can then go deeper and answer their own questions using the DataApps you’ve created.
We can use our Token Explorer DataApp to drill into specific wallets and days by just clicking, before composing our own query in the app showing change in the number of holders per day, seamlessly integrateing and interacting with the existing data.
Click to enlarge
We’ll have some deeper dives shortly, but here are some of the things we do differently.
Data for Web3 Analytics
We’re optimized for analytics, for ad hoc search and aggregations across all of the data. However, this is not unique as Snowflake and Big Query can all be recycled to do something similar. But these solutions need to serve all data considerations, predominately mutable Web2 data.
HyperArc is instead built for analytics on the blockchain’s immutable ledger and it’s data that is strictly additive. Capitalizing on this, we’re able to serve 10s of billions of searchable and aggregatable rows, streaming near real-time from finalization with sub-second queries. Data is stored at the lowest grain to support real time aggregations and filtering — gone are the days of even having to think about “re-indexing” as data needs change.
Semantic Layer
Most solutions today take an ELT approach to making blockchain data accessible. They extract hierarchical blockchain data just to normalize and load them into tables. These “raw” tables of event logs and function traces then need to be painstakingly reconstructed and transformed with complex joins by SQL experts in the community before any analytics can happen. They force you to think about your Web3 transactions as if they were modeled as Web2 tables.
We take a different approach with our Semantic Layer, replacing ELT with ETL under the hood, but with the actual goal for you to never have to think about ETL or ELT, or SQL for that matter. We want you to think about your data as native Web3 transactions, with all its transactional, call, and data hierarchy intact.
Our Semantic ABI (deep dive soon!) allows HyperArc users to simply annotate their existing ABI(s) with additional metadata. Tell us how the different parts of your nested structs across your functions and traces are important to you and how they augment each other in a transaction and we’ll handle the rest.
API
Our entire app is built API first from metadata to queries. Programmatically create or edit your DataApps to keep them up-to-date; or integrate the queries you’ve created in HyperArc into your data science pipelines; or flip it around and populate our composeable filtersets or labels from your ML models to be used in-app.
Everything possible in-app is also possible through our API. However, our APIs are opinionated (sorry GraphQL). Our keystone API is ArcQL which is designed for data access like SQL or GraphQL, but is opinionated and declarative. Although not a hammer for every nail, it ensures we know the intent of your queries for a no-code exploration experience, better visualizations, seamless breaking upgrades (no need to migrate from SQL V1 to V2 to V3), and out-of-the-box interactivity in our DataApps.
We’ve taken this approach for every API we design, from ArcQL to DataApps to Semantic ABIs, to ensure the UX is built with Web3 in mind. We’re working hard to thoughtfully support more so drop us a line if we’re missing your use case!
HyperArc is the first analytical platform that prioritizes usability to make it possible for all users, not just the most technical, to have transparent access to the blockchain.
What’s Next?
We have a couple of further deep dives coming soon, so keep an eye out on this blog! The first couple will cover...
Composability
Instead of monolithic code that answers 1 question, we want our users to collaborate and build analytical components that can be reused across queries to compose new insights.
Semantics from the Start
A deep dive into our semantic layer, a data transformation engine built just for Web3.
--
For now, please go ahead and try out HyperArc! We have three super useful DataApps for you to start exploring and discovering insights:
Let us know if you have any feedback!